
Así impactará la inteligencia artificial en el sector sanitario
En 2024 se producirá una aceleración en la adopción masiva de iniciativas que usen la inteligencia artificial.
4 marzo, 2024
6 min
¿Resulta adecuado apoyar en exclusiva las decisiones estratégicas de una compañía en la opinión, experta o no, de una o varias personas? Diversos estudios demuestran que el cerebro humano dispone de un componente poco estadístico por lo que existen mayores márgenes de error respecto al uso de otros sistemas de decisión apoyados, por ejemplo, en un algoritmo.
La opinión del ser humano al emitir juicios cuando la información es compleja es muy dispar, así se desprende del estudio realizado por Paul J. Hoffman, Paul Slovic y Leonard G. Rorer, en el que se presentó una radiografía de tórax varias veces a radiólogos expertos. En un 20% de las ocasiones, los radiólogos emitieron juicios contradictorios respecto a si la placa repetida era “normal” o “anormal”.
Asimismo, las decisiones del ser humano y la manera en la que realizamos predicciones pueden verse afectadas por el estado de ánimo. Según una investigación citada por el premio Nobel de Economía Daniel Kahneman, el porcentaje de sentencias favorables dictadas por jueces norteamericanos en un ensayo ascendía hasta el 65% después de que los magistrados hubieran hecho una pausa para comer, descendiendo esta cifra hasta niveles cercanos al cero, momentos antes de disfrutar de su siguiente descanso.
Es, por tanto, evidente que el papel que juega la información en este punto no es tan fundamental. La información es sólo la media naranja, la otra media es el método en el que se tratan dichos datos. Esta crítica-a la par que romántica metáfora- pone de relieve un elemento que muchos olvidan: demasiados datos no son una ayuda, sino más bien una tortura.
Ante este escenario, sería conveniente construir un modelo predictivo que pueda medir el impacto que las compañías registran al entrar en juego este tipo de variables más personales. Cualquier firma asegurará que es capaz de presupuestar el volumen de ventas con gran precisión en un área específica, para un producto específico y en unas condiciones específicas. Pero ¿sabría cuantificar con igual precisión las ventas que se está dejando por el camino? Imagine que pudiera establecer una simple ecuación que ligara la facturación en un mes con, por ejemplo, la habilidad del comercial, el número de clientes potenciales, el nivel de presencia de la competencia y las ventas en el periodo equivalente anterior.
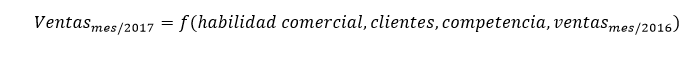
Con esta ecuación podríamos jugar, escoger una provincia, introducir los datos sobre la habilidad de nuestro comercial, el número de clientes, qué competencia existe, y las ventas del año pasado en esa misma zona y obtendríamos un valor esperado de ventas. Además, podríamos escoger otra combinación, por ejemplo comercial-zona, y contemplar si el resultado es mejor o peor. Asimismo, permitiría simular un aumento de la presencia de la competencia, obteniendo el nuevo volumen de facturación en este escenario de riesgo. Podríamos cuantificar, también, qué efecto en la facturación tiene que nuestro comercial estrella decida dejar la empresa y haya que sustituirlo con otro profesional de desempeño no tan estelar.
Los resultados obtenidos por este método, aunque gozaran de un alto grado de acierto, no tendrían una fiabilidad del 100% ya que los algoritmos no tienen hambre como los jueces, ni cambian de opinión al enfrentarse a placas de tórax complicadas como los radiólogos. Parece, por tanto, razonable apoyar las decisiones en este tipo de información, que puede complementar a la perfección un juicio experto.


Deja un comentario